Landscape of Quantum Computing in 2021
See here for the 2023 update, and the 2022 update.
Quantum computers have a lot of potential, but how far are we from that potential? When will all of our RSA keys be obsolete? When will -- as Microsoft hopes – quantum computers solve climate change?
I drew a quick sketch of my impressions of the field on Twitter, and Steve Weis asked for a more detailed treatment. Here is a more accurate picture of that sketch:
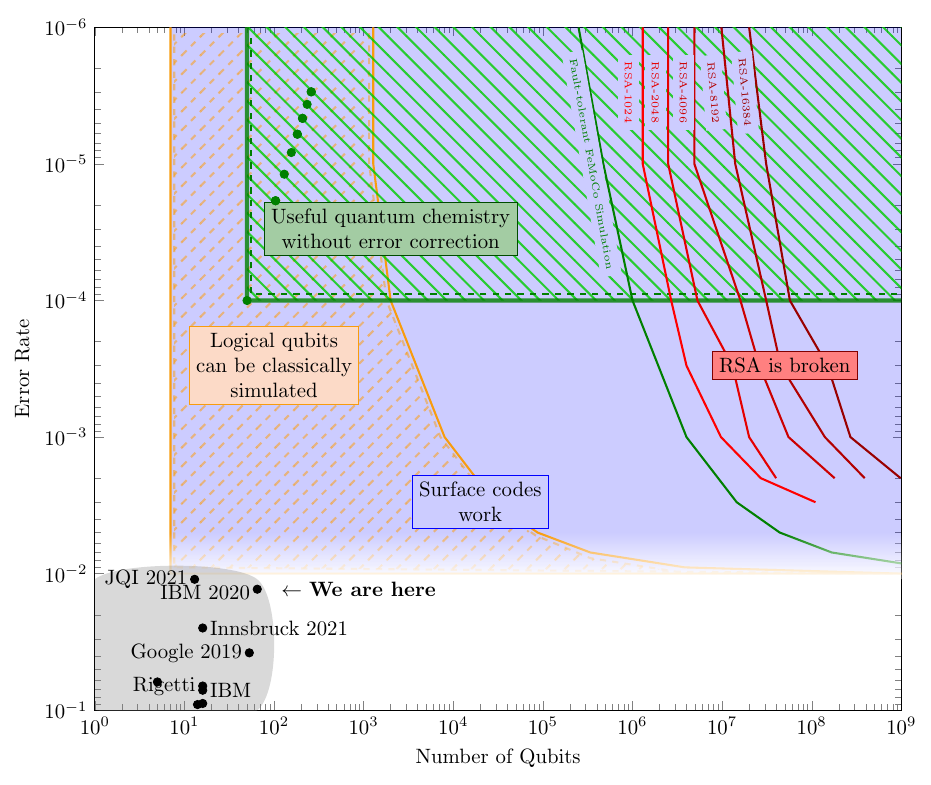
(Undoubtedly this chart is still incomplete. If you think some of the points on this chart should move, please send me a message and ideally a citation!)
Some terminology: A qubit is the basic unit of data in a quantum computer, and it can store a 1 or a 0 just like a classical bit, but also superpositions of those two states. A gate is an operation applied to a qubit, such as flipping a 0 to a 1, or changing the quantum phase, or XOR, etc.
To explain this chart: quantum data is very fragile. Most types of qubits today can only hold onto a quantum state for a few microseconds before they lose it – either they drift to another quantum state unpredictably, or they interact with the environment and "collapse" any superposition they had.
Not only that, any gate applied to the qubit has some chance of causing error. Today’s qubits are close to 1% gate error. Imagine if every time you sent a bit through a transistor, there was a 1% chance of flipping the bit. You could hardly perform any computation at all!
Google’s Sycamore chip, famous because it seems to be able to solve a (useless) computational problem faster than any classical computer, can only do about 20 gates in a row before being reduced to useless noise. To break RSA-2048 would require more than 2.1 billion gates in a row.
For quantum computers to be useful, we need more qubits but we also need better qubits.
Rather than make each qubit a billion times better, the agreed-upon approach is to make them about 10-100 times better, then assemble these qubits together with an error-correcting code. The individual qubits on the chip are known as physical qubits, and connecting together 100s or 1000s of physical qubits can give one logical qubit. Without improving the quality of the individual physical qubits, the error rate of the logical qubits can be reduced exponentially just by bundling more physical qubits into each one. The only catch: the physical qubit error rate must be lower than a certain threshold before the code will function at all.
A quantum computer that uses error correction to push qubit and gate errors to 0 is called fault-tolerant.
The front-runner for a quantum error-correcting code is called a surface code. The blue region in the chart is where physical qubits are good enough to form logical qubits in a surface code. After some feedback, I added a fade to the bottom of that region, since we're not exactly sure what the threshold is (very likely between 0.1% to 1%, but it depends on what kind of errors happen).
We’re very close to this! However: If we need 100 physical qubits to make a single logical qubit, then that increases our qubit requirements by a factor of 100. And 100 is an underestimate: longer algorithm’s like Shor’s algorithm (to break RSA) likely require more than 1000 physical qubits per logical qubit.
There has been some talk about quantum computers reaching a point where they cannot be simulated classically. Quantum computers have already passed this point, since classical computers can only simulate about 40 qubits (each qubit doubles the time or memory complexity of the simulation, so even huge classical computers can’t go much higher than this).
However, once we start bundling physical qubits into logical qubits, then the number of qubits which are actually useful (the logical qubits) is much lower than the number of physical qubits. Even if we have 40,000 physical qubits, if we only get 40 logical qubits once we bundle them together for error correction, then any algorithm on those logical qubits is still within reach of classical computers.
The yellow-///-striped region of the chart is where we can’t simulate all the physical qubits, but there are so few logical (error-corrected) qubits that we can classically simulate any error-corrected algorithm.
The bottom left region is bad for quantum computers: if the gate error is 10-3, we can only run about 1000 gates on the physical qubits, probably not enough to do anything useful. But we can’t make enough logical qubits to do anything useful, either!
Once we have decent error rates (say, 10-3) then we just need to build lots of qubits and we can start doing useful things. However, the number of qubits for these fault-tolerant algorithms can be very high.
The green line shows the minimum requirements for a chemical simulation of FeMoCo, a molecule involved in producing ammonia from atmospheric nitrogen.
The red lines show the minimum requirements to run Shor’s algorithm to break RSA keys of various sizes.
What about to the left of that green line? If you had 10,000 qubits but 1 in 1000 gates caused an error (i.e., 100x more qubits and 10x less error than today), could you still do something useful? We’re not sure. There are promising approaches, mainly variational quantum algorithms, which can be more robust against noise and can use error reduction techniques with lower overheads but less benefit than full fault-tolerance. The problem with these is that there are few provable guarantees on their effectiveness. They might work really well, or they might not, and maybe we won't even know until we can actually build a quantum machine and try them. There is a lot of research in this area, under the term “NISQ”: Noisy Intermediate Scale Quantum computers.
The green-\\\-striped region shows where we can solve some chemistry problems using quantum computers, without needing full error correction. The green dots are resource counts for some specific problems.
From this chart, here is my opinion on the prospects of quantum computing:
- Outside of the green striped region and to the left of the green line, quantum computers might be useless. This is a region where we cannot run any quantum algorithm which outperforms classical computers. Though, we may discover new algorithms which could run on a quantum computer in this region.
- We need Moore’s-law type scaling for quantum computers to ever be useful. This is a log plot. If we ever want to get to the regions on the top or the right, we need to be scaling exponentially in some dimension.
- There may be a sharp transition from “quantum computers are useless” to “quantum computers break RSA”. If we do get exponential scaling, then the distance we have to cover from here to the green line (the first useful application on this chart) is much farther than the distance from there to where all reasonable RSA sizes are broken.
- The green-striped region will probably move down.
- First, it’s the most outside of my expertise and the most likely for a paper that I don't know about.
- Second, there is a lot of research in this area.
- Third, these are exactly the kind of problems where I would expect the real-world performance of algorithms to vastly exceed the worst-case performance of a theoretical analysis. But we won’t get to see that real-world performance until the big quantum computers are built!
- The red lines probably won't move much. Unlike with variational problems, we can estimate the runtime and success probability of Shor's algorithm with known algorithms very precisely. Moreover, Shor's algorithm is mainly just modular exponentiation, meaning that it's about as hard for a quantum computer to use RSA as it is to break RSA. An asymptotic improvement is highly unlikely, though small algorithmic improvements and better codes will probably develop and shift the curves a bit to the left. Also, variational algorithms won't break RSA.
- A big breakthrough could change this whole chart - but a big breakthrough could also break factoring classically. If someone comes up with a code much better than the surface code, then this all radically changes; if someone beats O(n2/log n) multiplication on a quantum computer, the red lines move. But these would be big innovations; we could also get a polynomial-time classical factoring algorithm. How do we decide which scientific breakthroughs are plausible, and which aren’t?
- Even though quantum computers are far away, you should still replace RSA and ECC. Michele Mosca pointed out the main problem: Suppose quantum computers that can break RSA-2048 are 30 years away. If it will take 10 years to standardize new cryptography, 10 years for your organization to implement it, and you need your secrets to remain safe for 12 years, then you’re already 2 years too late, since someone can record your encrypted data and break it later. Basically, it’s a race between the world’s most brilliant quantum engineers and the world’s laziest sysadmins, where the sysadmins have about a 30 year headstart.
Feedback
I posted this on Twitter and received good feedback, which I partially address here:
- Rodney van Meter says that architecture and clock speed are important to consider as well. Getting to 10 million qubits hides a lot of architectural issues: are we really going to build a stadium-sized chip and a refrigerator to house it? Probably not; instead we'll either switch to a new technology or connect many smaller processors. Either way we may end up needing to change the circuits/algorithms to fit the architecture. The fault-tolerant lines on the chart assume a huge, 2-dimensional grid of qubits, each connected only to its neighbours. I mildly disagree about clock speed: today's gates are about as fast as they need to be run the fault-tolerant algorithms on this chart in a matter of hours to weeks. If we move to a different technology, though, maybe we get lower errors but longer gates, and gate times will be limiting.
- BSI Bund has a similar chart (pg. 208, Fig. 21.1). They plot qubits*depth, which is a more meaningful thing to count, but probably more confusing if you're new to quantum computing.
- This chart might be overoptimistic in a few ways: Some people doubt the threshold theorem altogether (it's proven based on uncorrelated errors, so if that assumption is wrong in practice, the codes won't work as expected), and the usefulness of the "useful" quantum chemistry is debatable. Simulating FeMoCo doesn't necessarily give us any better method to produce nitrogen fertilizer, and even if it did, that doesn't fix the unsustainable farming practices that need so much fertilizer. The other quantum chemistry dots aren't huge open problems in the field, but just real-world problems that are beyond classical computing power.
- Google's chip is closer to the surface code threshold than this chart shows, since I used the readout error and other types of error are much lower. There is a complicated relationship between the threshold and the various types of error that I don't fully understand.
- The reason the yellow region of simulatable logical qubits doesn't extend further down/left is because there are no logical qubits in that region. There's also a region where we can simulate all physical qubits, but adding that would clutter the chart.
- To break elliptic curve cryptography (from 256 to 512 bits), the lines are roughly around the FeMoCo simulation line. There is no analysis of quantum elliptic curve circuits with as much detail as for RSA, so the lines would be less accurate.
Chart methodology
- Current chips (I didn’t read any of these papers carefully, I just took the numbers):
- Google’s gate error is based on readout error from this talk. Readout error might be unfair to Google here (especially since I couldn't find it for IBM's chip). I excluded the Bristlecone chip because its performance hasn’t been as impressive, despite higher qubit counts.
- Innsbruck was based on a 2.5% error rate in XX-rotations.
- Bottom IBM and Rigetti come from this survey paper; I took the largest type of error in every case.
- Top IBM was from this IBM paper, where I used 1 - fidelity as error.
- For JQI (Joint Quantum Institute) I also used 1 - fidelity, with the mid-point of their fidelity estimate (98.9%).
- IBM recently announced a 127 qubit chip that's not on this chart because they haven't released on data on error rates yet.
- The red lines for RSA came from the python script with this paper. The script crashes if the physical error rate is too close to the threshold, so I took the lowest rate before the program crashed.
- Yellow region is based on a surface code where the error at distance d is given by 0.1*(e/0.01)(d+1)/2, where e is the physical error rate, and requiring error of 10-6 overall (less than that and it’s probably not a very useful algorithm).
- The green line used the same surface code formula to extrapolate the numbers from this paper to different physical error rates.
- The green region is based on this paper, which needs 50 qubits and gate errors less than 10-4, and also this paper. In the second paper I took the number of qubits from Table 4, and assumed the error must be the inverse of (# of qubits)*(circuit depth), where circuit depth was 5*(# of qubits) -3. Since anything above and to the right of any of those dots would also be able to compute the same algorithm, that was where I drew the green region.